迁移学习
在工程实践中,从头构建一个神经网络是非常耗时的,因此我们会将已经训练过的模型进行调整,或者是利用相似的模型完成不同的任务,这都是属于迁移学习。
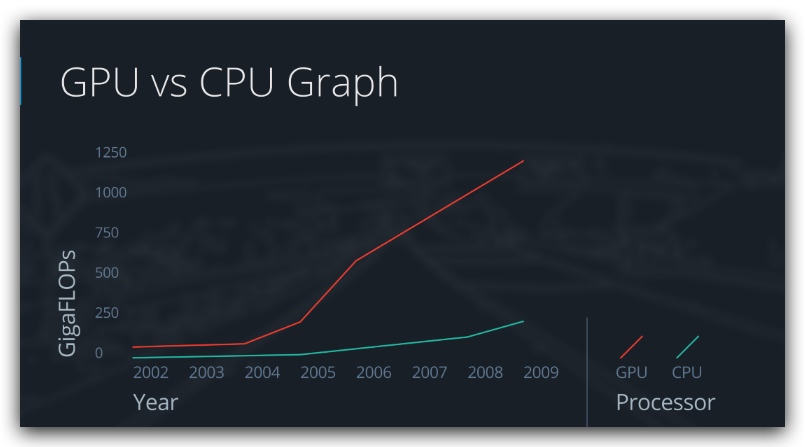
GPU vs CPU
使用GPU可以将训练速度提高5倍以上,知名的库有cuDNN
迁移学习
使用迁移学习依赖于:
- 新数据集的大小
- 新老数据集的相似性
通常有以下四种场景:
- 新数据集很小,新数据集和老的训练数据相似
- 新数据集很小,新数据集和老的训练数据不一样
- 新数据集较大,新数据集和老的训练数据相似
- 新数据集较大,新数据集和老的训练数据不一样

一个预先训练好的模型
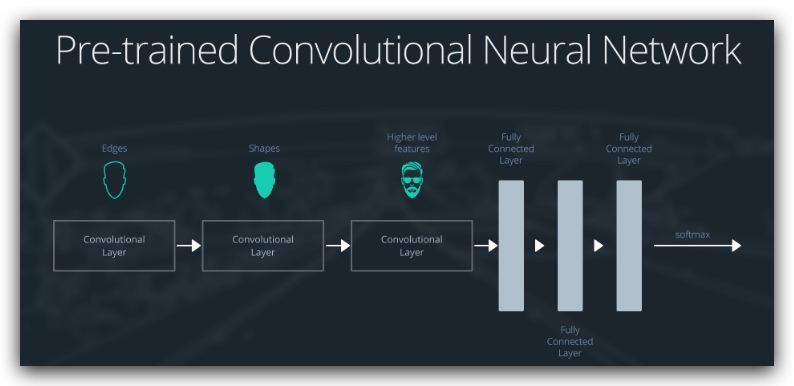
- the first layer will detect edges in the image
- the second layer will detect shapes
- the third convolutional layer detects higher level features
Case 1: Small Data Set, Similar Data
slice off the end of the neural network add a new fully connected layer that matches the number of classes in the new data set randomize the weights of the new fully connected layer; freeze all the weights from the pre-trained network train the network to update the weights of the new fully connected layer
ImageNet
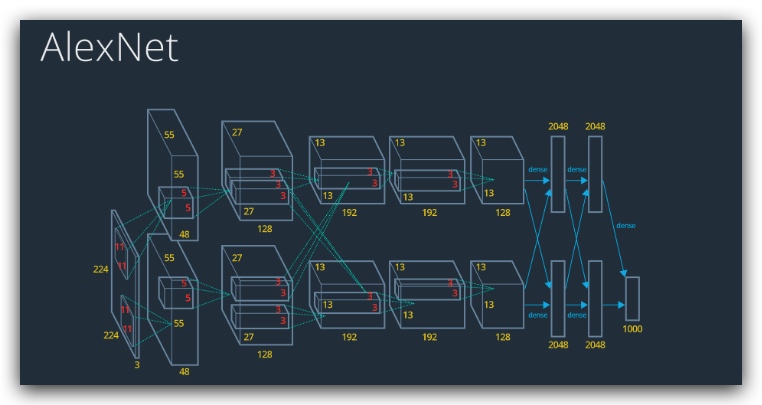
AlexNet
模型共8层,使用了GPU进行模型训练
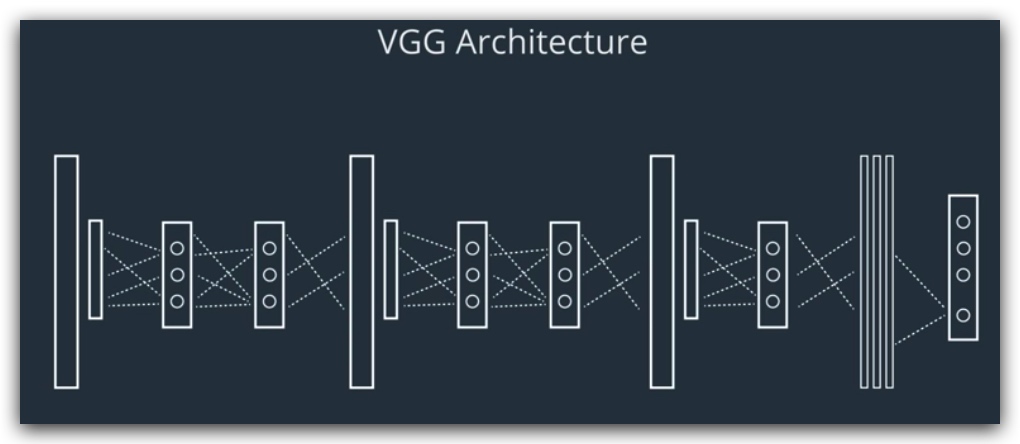
VGG
模型共19层,3x3卷积,中间由2x2的池化层隔开,最后是连续3个全连接层
GoogLeNet
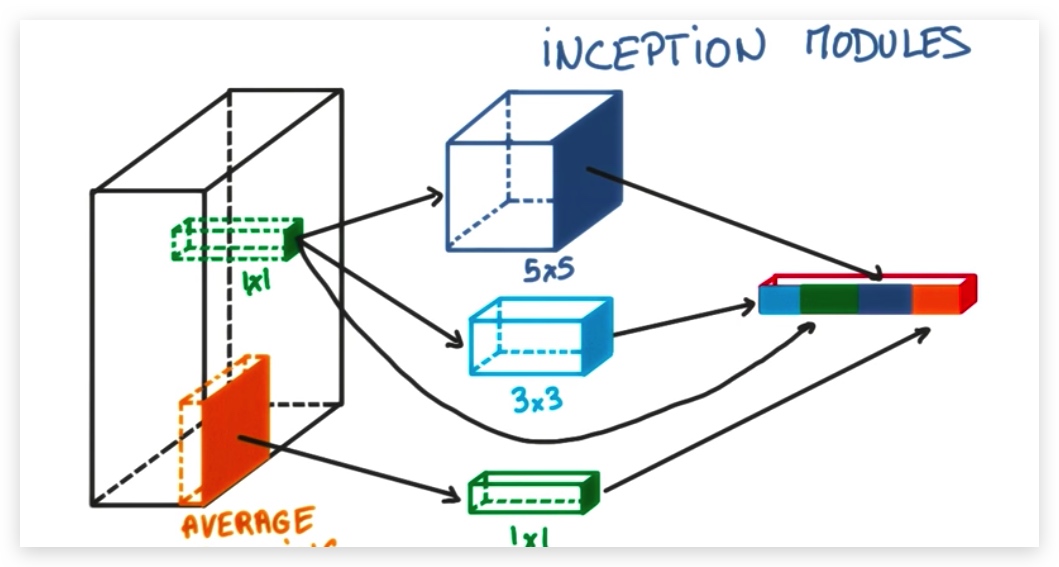
模型共22层。引入了interception模块,使的超参数非常少,因此训练速度很快。错误率7%左右
ResNet
微软提出,模型有152层。错误率3%,甚至比人还强。通过增加连接来跳过一些层,确保深层网络可以被训练到。
translator: http://www.jobbole.com/members/q3014225652/ reviewer: http://www.jobbole.com/members/hanxiaomax/ via: https://www.tutorialdocs.com/article/regex-trap.html