卡尔曼滤波
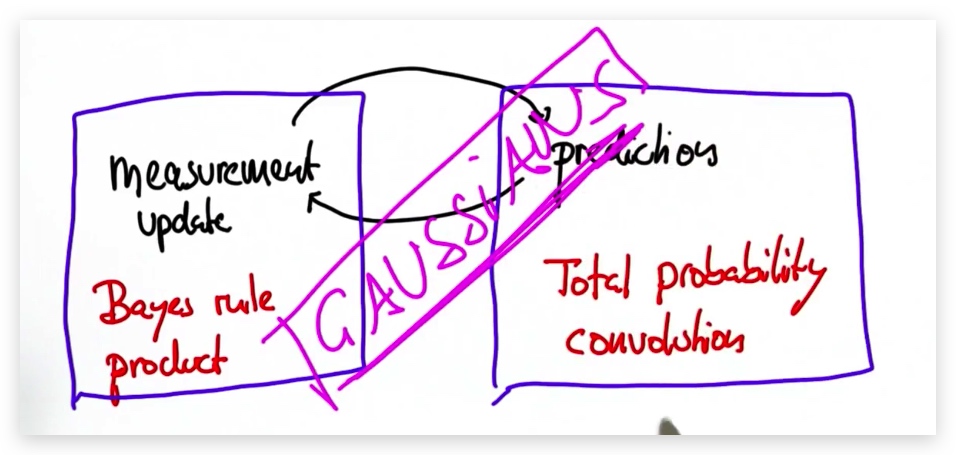
1. 更新循环和移动循环
- 更新循环 基于乘法法则和贝叶斯定律
- 移动循环(预测) 基于卷积和全概率公式
2. 测量更新
数学原理
测量的更新,基于乘法法则和贝叶斯定律。 首先我们有一个先验的测量值,然后得到一个新的测量值,两者均为正态分布。使用贝叶斯定律,我们可以得到后验概率,也就是我们更新测量后的结果
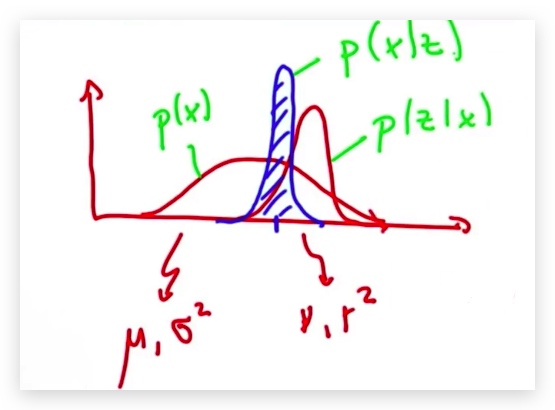
P(X|Z) = P(Z|X)P(X)/P(Z) 叠加之后的正态分布参数为 $ \mu^2=\frac{\mu* r^2 + \gamma*\sigma^2}{r^2+\sigma^2} $
$ \sigma^2=\frac{1}{\frac{1}{r^2}+\frac{1}{\sigma^2}} $
代码
def update(mean1, var1, mean2, var2):
new_mean = (mean1*var2+mean2*var1)/(var1+var2)
new_var = 1/(1/var1 + 1/var2)
return [new_mean, new_var]
3. 移动更新(预测过程)
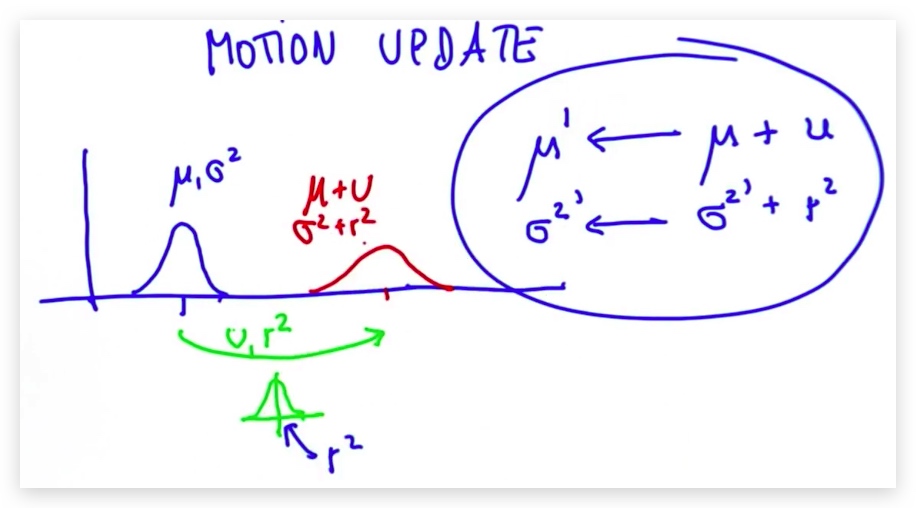 预测过程基于卷积和全概率公式
预测过程基于卷积和全概率公式
数学原理
假设我们处于一个初始位置,然后进行一次移动,移动本身是有误差的,两个事件都服从正态分布。则结果也是正态分布
$ \mu'=\mu + u $
$ \sigma'^2 =r^2+\sigma^2 $
代码
def predict(mean1, var1, mean2, var2):
new_mean = mean1+mean2
new_var = var1+var2
return [new_mean, new_var]
4. 一维卡尔曼滤波代码
# 更新函数
def update(mean1, var1, mean2, var2):
new_mean = float(var2 * mean1 + var1 * mean2) / (var1 + var2)
new_var = 1./(1./var1 + 1./var2)
return [new_mean, new_var]
# 预测函数
def predict(mean1, var1, mean2, var2):
new_mean = mean1 + mean2
new_var = var1 + var2
return [new_mean, new_var]
measurements = [5., 6., 7., 9., 10.] # 测量值
motion = [1., 1., 2., 1., 1.] # 移动距离
measurement_sig = 4 # 测量方差
motion_sig = 2 # 移动方差
# 初始值
mu = 0.
sig = 10000.
for i in range(len(measurements)):
[mu,sig]=update(mu,sig,measurements[i],measurement_sig)
print("update:",[mu,sig])
# 使用更新的均值和方差进行预测
[mu,sig]=predict(mu,sig,motion[i],motion_sig)
print("pridict:",[mu,sig])
print [mu, sig]
('update:', [4.998000799680128, 3.9984006397441023])
('pridict:', [5.998000799680128, 5.998400639744102])
('update:', [5.999200191953932, 2.399744061425258])
('pridict:', [6.999200191953932, 4.399744061425258])
('update:', [6.999619127420922, 2.0951800575117594])
('pridict:', [8.999619127420921, 4.09518005751176])
('update:', [8.999811802788143, 2.0235152416216957])
('pridict:', [9.999811802788143, 4.023515241621696])
('update:', [9.999906177177365, 2.0058615808441944])
('pridict:', [10.999906177177365, 4.005861580844194])
[10.999906177177365, 4.005861580844194]
5. 多维高斯分布
在多维高斯函数中,均值变成了一个向量,方差变成了协方差矩阵。其概率密度如下:
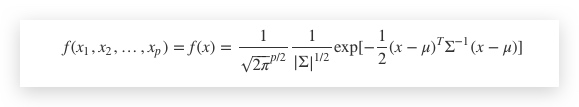
针对二维高斯分布,协方差矩阵的对角线元素为X1与X2轴的方差,反斜对角线上的两个值为协方差,表明X1与X2的线性相关程度,(正值时:X1增大,X2也随之增大;负值时:X1增大,X2随之减小)。
- 如果两个变量无关,则协方差矩阵为一个圆
- 不确定越大,圆越大
- 也可能在一个方向上不确定大,另一个方向不确定小,则为椭圆
- 如果两个维度相关,则椭圆为斜的,所谓相关,指的是我们可以以一个维度推断另一个维度。通过(X0 ,Y0),则可以推断(X1 ,Y1)
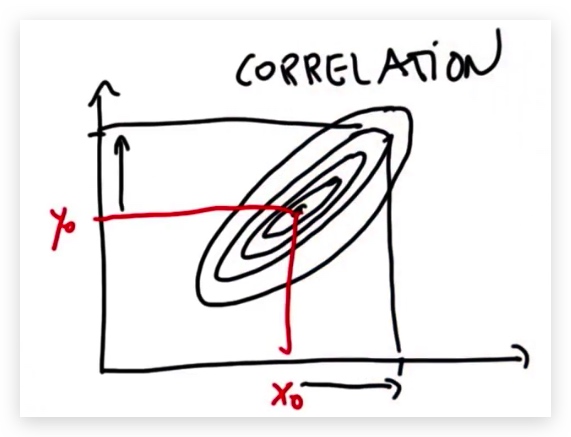
6. 基于多维高斯函数的预测
在平面上,基于一维的高斯,我们可以预测位置,同样的,在二维的空间中,我们也可以进行预测。
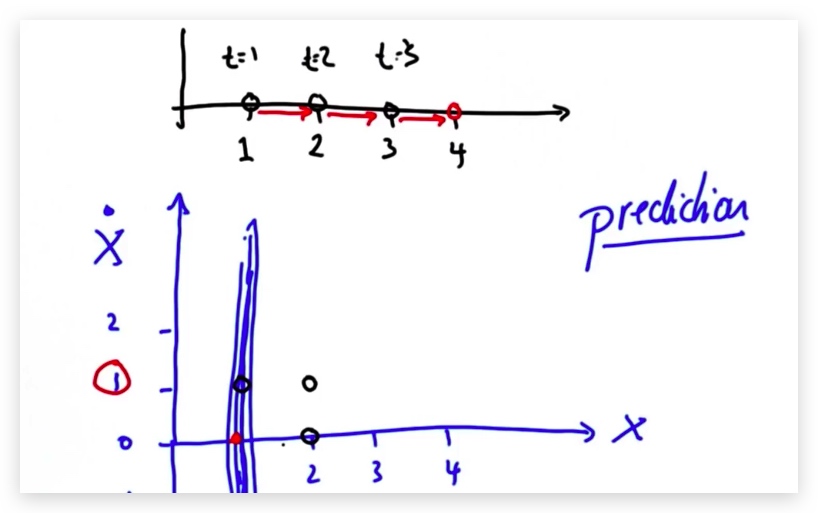
我们可以测量X,不能测量速度,但是速度是位置的导数,所以我们说两个维度是有相关性的。在测量过程中,我们可以测得X,此时我们对速度一无所知。在预测过程中,我们可以假设一个速度,这样就能知道X在此速度下,T+1时的位置X。
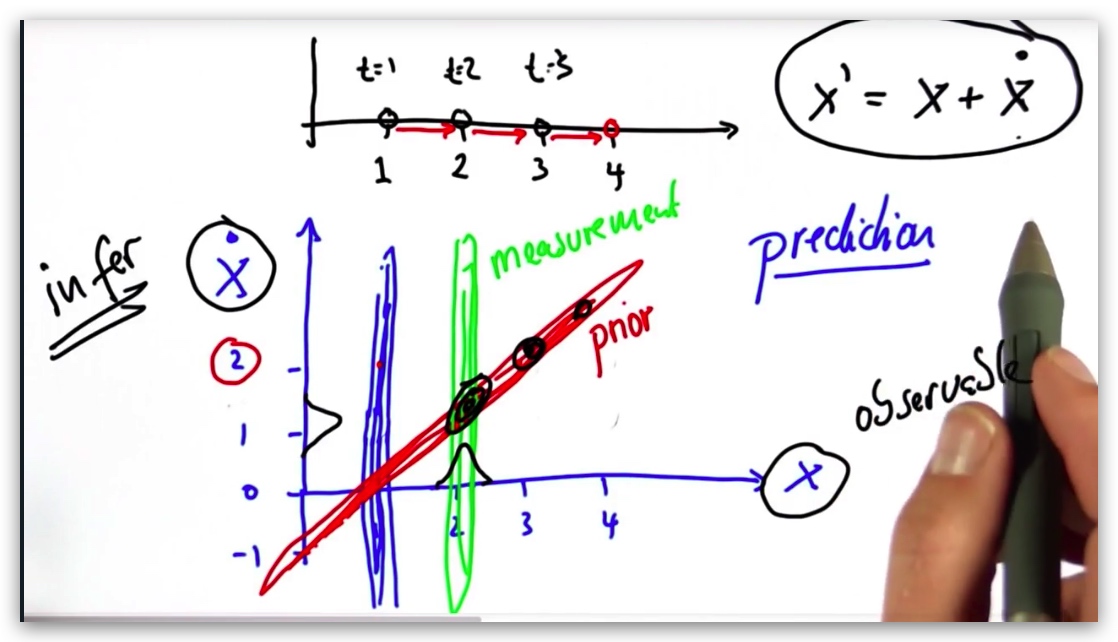
上图诠释了卡尔曼滤波的核心概念。
首先我们知道了X和速度V(X导数)的关系,X = Vt,也就是红色的椭圆。但是显然,斜椭圆表示两者是相关的。但是如果我们将红色椭圆投影到X或X点方向上,我们都无法进行预测,因为不论投影在哪个轴,我们都缺少另一个变量的信息。即单次观察和单次预测都无法确定观察结果。
由于红色是我们已知的规律,所以它是一种先验概率(prior),如果我们再对X进行一次观察,得到X的条件概率(measurement),然后依据贝叶斯定律将两者相乘,我们就可以得到后验概率(预测),后验概率一定相交于在红色椭圆上,它也是一个椭圆(二维高斯),且在两个维度上可以鸽子得到一个高斯函数,预测相关维度。经过不断的测量和预测,我们注意到,红色椭圆上的黑色椭圆越来越小,表示不确定性逐渐减小(方差减小了)
这深刻的揭示了卡尔曼滤波器的原理,我们只能观察一个值的时候,就可以利用贝叶斯推断另外一个值(通过先验知识——例如物理方程)
卡尔曼滤波器可以预测一段时间后我的位置,x' = x + Δtẋ',且该方程在后续的预测中可以作为约束条件。利用该约束条件,我们就可以通过x来预测速度(本身不能观察)
7. 设计卡尔曼滤波器

# Write a function 'kalman_filter' that implements a multi-
# dimensional Kalman Filter for the example given
########################################
# Implement the filter function below
def kalman_filter(x, P):
for n in range(len(measurements)):
# measurement update
Z = matrix([[measurements[n]]]) # 测量值
y = Z - (H * x) # 新的测量值矩阵
S = H * P * H.transpose() + R #用于计算K,卡尔曼增益的分母
K = P * H.transpose() * S.inverse() #卡尔曼增益
x = x + ( K * y) # 新的估计值
P = (I -(K * H)) * P # 新的估计误差
# prediction
x = (F*x) + u #
P = F * P * F.transpose()
return x,P
############################################
### use the code below to test your filter!
############################################
measurements = [1, 2, 3]
x = matrix([[0.], [0.]]) # initial state (location and velocity)
P = matrix([[1000., 0.], [0., 1000.]]) # initial uncertainty
u = matrix([[0.], [0.]]) # external motion
F = matrix([[1., 1.], [0, 1.]]) # next state function
H = matrix([[1., 0.]]) # measurement function
R = matrix([[1.]]) # measurement uncertainty
I = matrix([[1., 0.], [0., 1.]]) # identity matrix
print(kalman_filter(x, P))
# output should be:
# x: [[3.9996664447958645], [0.9999998335552873]]
# P: [[2.3318904241194827, 0.9991676099921091], [0.9991676099921067, 0.49950058263974184]]